Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
Evaluating the Model: Risk Chart |





|
Todo: Move this to the evaluation chapter. Too complex for getting started.
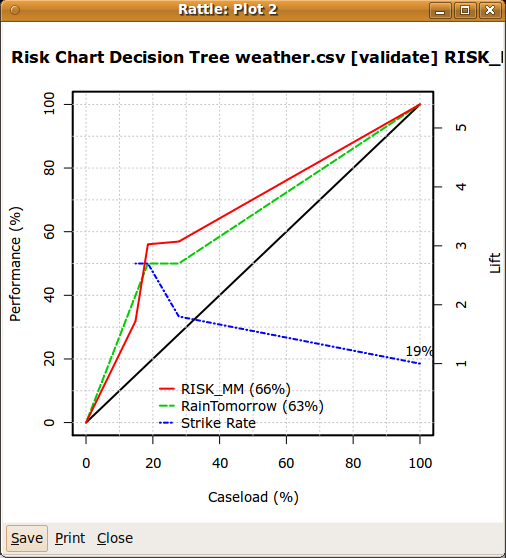
Another form of evaluation is what we call the risk chart, which is also known as a cumulative gain chart. A risk chart can be used for a different kind of interpretation of our model.
We can think of the leaf nodes of the model as assigning a probability to each observation. In our weather data this is the probability that it will rain tomorrow. Have a look again at Figure 2.5. The leaf nodes include a percentage, which is the percentage of observations at that node that have the majority decision. Thus, for node 23 all 13 observations are associated with days where there is rain on the following day. Thus, for any day that meets the associated conditions we would assign to our prediction for it to rain tomorrow a score of 100%. For node 3, for example, we would assign a score of 84.6%, and for node 4 we would assign a score of just 7.8% (since that node predicts that it won't rain with a 92.2% confidence).
Now consider scoring all observations in the testing dataset in this way. Observe that the decision tree only supports a small number of distinct scores: 100%, 84.5%, 28.6%, 7.8% and 6.2%. Effectively, a decision tree will group the observations according to these scores.
Suppose we order the observations in the testing dataset, from left to right, so that those with the highest score (i.e, most likely to rain the next day) are to the left. We then record for each score (i.e, each group, as noted above) the number of observations where it genuinely did rain the following day and we plot these, in a cumulative manner. The resulting plot is the dashed line (RainTomorrow) we see in Figure 2.9.
In brief, the solid diagonal line in a risk chart can be thought of as a baseline. This represents the situation if we have no model and we purely randomly predict whether it will rain tomorrow. If we randomly pick 50% of the population (e.g., randomly pick 50 days out of 100) then we would expect to obtain a 50% performance. That is, we would expect that, if it rained 20 of those 100 days, then our 50% selection would have 10 days where it rained.
The dashed line then reports the model performance. We can see that if we ordered the days according to the strength of the score from the model then we actually get more than 65% performance. That is, amongst the 50 observations we expect to hit 12 or 13 days of rain.
How is this useful? Consider a different goal--a goal other than wanting to know whether we should carry an umbrella tomorrow. Suppose we have a different scenario -- we want to collect water in our water starved city. When there is a good chance of rain we want to deploy some water capture device (perhaps a bucket). On the other hand, we want to avoid putting the bucket out unnecessarily, for whatever reason (maybe because it is likely to be stolen or perhaps it deteriorates quickly in the sunshine). In some way there is a cost associated with putting the bucket out and we want to minimise this cost, whilst capturing as much water as possible. Another assumption is that we can only choose to either put the bucket out in the morning and leave it there all day, or not put the bucket out at all (perhaps we need to go to work during the day).
The risk chart gives us a guide as to how to optimise our strategy for water collection. A tradeoff between limiting the number of days we put the bucket out and getting the most water collected might lead us to put the bucket out on only some 15% of the days which will deliver us close to 50% of the days on which there was rain. This compares to the baseline, where we put the bucket out randomly, whereby we would only capture 15% of the days of rain, rather than 50%. That's quite a gain (or, formally, that's quite a lift in performance).
We may have noticed that there is a variable listed in the Data tab which has been given the role of being a Risk variable (it is outside the frame in Figure 2.3 but if we scroll down we'll see it). The RISK_MM variable records the amount of rain observed for the following day. This data is used as a measure of size of some kind of risk. Our risk here is in not getting enough water. We note that when it rains, we get different amounts of rain during the day.
The solid line of the risk chart records the amount of actual rain that we capture when we do put out our bucket according to the strategy we have just described. This line can also play a role in helping to decide how many days we should put our bucket outside. This will be explained in Chapter 22.
Finally, note that the x axis of the plot is labelled as ``Caseload''. This reflects a common situation in which we apply data mining (e.g., selecting cases for investigating fraud). In such scenarios we talk of a caseload as being the number of cases that we select, and the performance relates to how many of those cases were actually found to be genuine frauds. Caseload makes more sense in this scenario.
We have now stepped through some of the process of data mining. We have loaded some data, explored the data, possibly cleaned and transformed the data, built a model, and evaluated the model. It is now ready to be deployed. Of course, there is a lot more to what we have just done than what we have covered here. The remainder of the book provides these details. Before proceeding to the details, though, we might review how we interact with R and with Rattle.