
Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
Loading a Dataset |





|
With Rattle we can load a sample dataset in preparation for modelling, as we have just done. The sample dataset is a publicly available dataset which can be downloaded from the Australian Bureau of Meteorology. We modify the data a little for the data mining task.
If we have followed through the four steps above, in Section 2.3, then we will now need to reset Rattle. Simply click the New button within the toolbar. We are asked to confirm that we would like to clear the current project.
Alternatively we might have exited Rattle and R, as described in Section 2.1, and need to restart everything, as also described in Section 2.1.
Either way, we need to have a fresh Rattle ready so that we can follow the examples below.
On starting Rattle we can, without any other action, click the Execute button in the toolbar. Rattle will notice that no CSV file has been specified (notice the ``(None)'' in the Filename: chooser) and will ask whether we wish to use one of the sample datasets supplied with the package. Click on Yes to do so, to see the data listed, as shown in Figure 2.3.
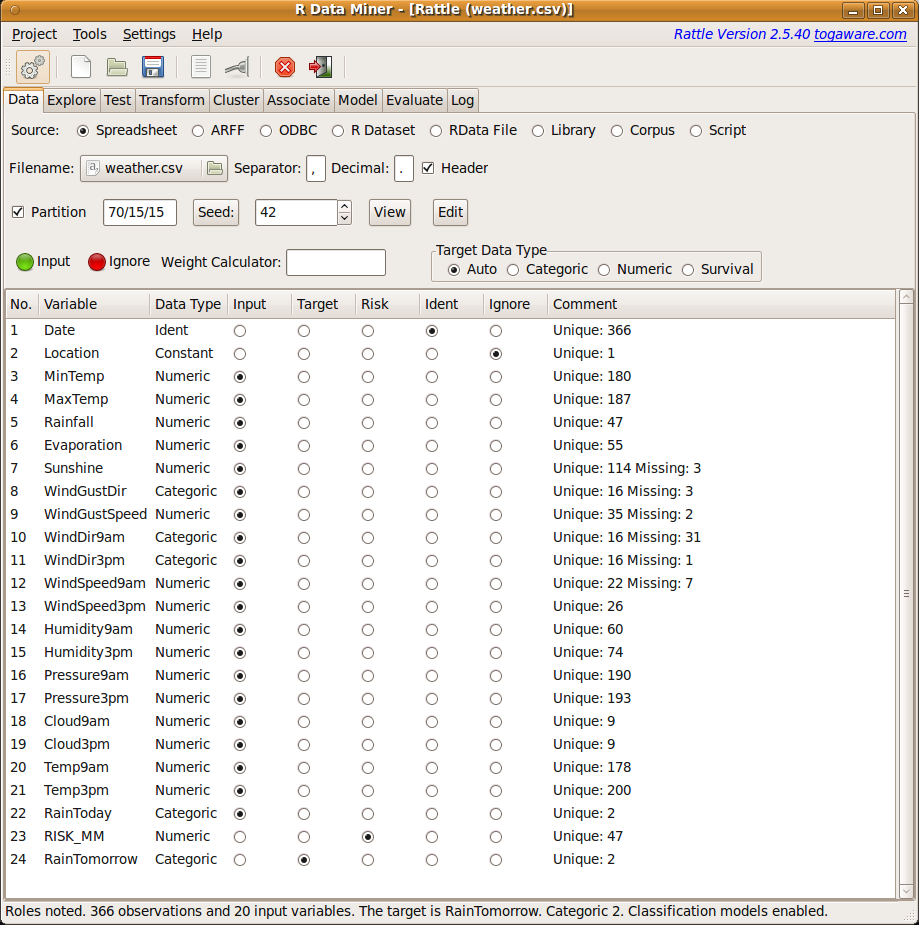 |
The file weather.csv has been read by default, and loaded into Rattle as its dataset. Within R a dataset is actually known as a data frame.
The dataset summary provides a list of the variables, their data types, default roles, and other useful information. The types will generally be Numeric (if the data consists of numbers, like temperature, rainfall, and wind speed) or Categoric (if the data consists of characters from the alphabet like the wind direction which might be N or S, etc.) though we can also see an Ident (identifier). An Ident is often one of the variables (columns) in the data that uniquely identifies each observation (row) of the data. The Comments column includes general information like the number of unique (or distinct) values the variable has, and how may observations have a missing value for a variable.