
Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
Loss Matrix |





|
The loss matrix is used to weight mis-classifications differently. This refers to the false positives (or type I errors) and false negatives (type II errors), when we talk about a two class problem. Often, one type of error is more of a loss to us than another type of error. In fraud, for example, a model that might identify too many false positives is probably better than a model that identifies too many false negatives (because we then miss too many real frauds).
The default loss for each case is 1--they are all of equal impact or loss. In the case of a rare, and underrepresented class (like fraud) we might consider false negatives to be 4 or even 10 times worse than a false positive. Thus, we communicate to the model builder that we want it to work harder to build a model to find all of the positive cases.
The loss matrix records these relative weights, for the two class
case, as:
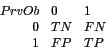
In general, the loss matrix must have the same dimensions as the number of classes (i.e., the number of levels of the target variable) in the training dataset. For binary classification we must supply four numbers with the diagonal as zeros.
An example is the string of numbers ![]() , which might be
interpreted as saying that an actual 1, predicted as 0 (i.e., a false
negative) is 10 times more unwelcome that a false positive!
, which might be
interpreted as saying that an actual 1, predicted as 0 (i.e., a false
negative) is 10 times more unwelcome that a false positive!
The loss matrix is used to alter the priors which will affect the choice of variable to split the dataset on at each node, giving more weight where appropriate.
Using the loss matrix is often indicated when we build a decision tree that ends up being just a single root node (often because the positive class represents less than 5% of the population--and so the most accurate model would predict everyone to be a negative).