
Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
|





|
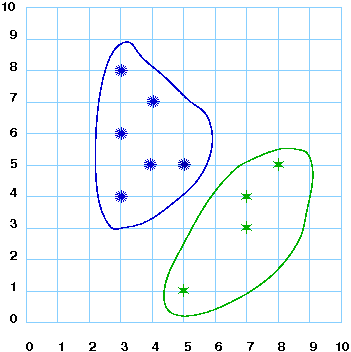
The amap package includes k-means with a choice of distances like Eulidean and Spearman.
. We optimize implementation (with a parallelized hierarchical clustering) and allow the possibility of using different distances like Eulidean or Spearman (rank-based metric).