Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
|





|
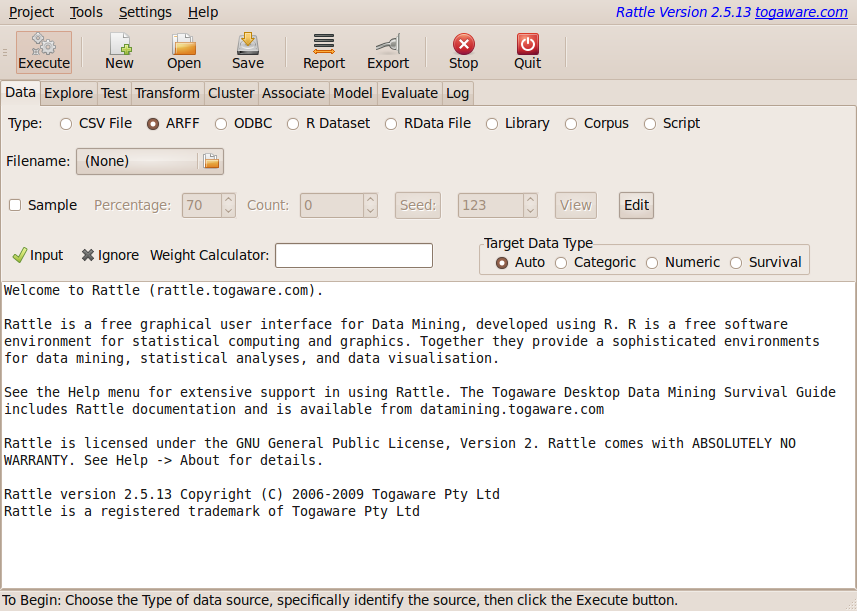
The Attribute-Relation File Format (ARFF) is an ASCII text file format that is essentially a CSV file with a header that describes the meta-data. ARFF was developed for use in the Weka machine learning software and there are quite a few datasets in this format now. We can load an ARFF dataset into Rattle through the ARFF option (Figure 4.4).
An example of the ARFF format for our audit dataset is
shown:
@relation audit
@attribute ID numeric
@attribute Age numeric
@attribute Employment {Consultant, PSFederal, PSLocal, ...}
@attribute Education {Associate, Bachelor, College, Doctorate, ...}
@attribute Marital {Absent, Civil, Divorced, Married, ...}
@attribute Occupation {Cleaner, Clerical, Executive, Farming, ...}
@attribute Income numeric
@attribute Gender {Female, Male}
@attribute Deductions numeric
@attribute Hours numeric
@attribute Accounts {Canada, China, Columbia, Cuba, Ecuador, ...}
@attribute Adjustment numeric
@attribute Adjusted {0, 1}
@data
1004641,38,Private,College,Separated,Service,71511.95,Female,0,...
1010229,35,Private,Associate,Unmarried,Transport,73603.28,Male,...
1024587,32,Private,HSgrad,Divorced,Clerical,82365.86,Male,0,40,...
1038288,45,Private,?,Civil,Repair,27332.32,Male,0,55,...
1044221,60,Private,College,Civil,Executive,21048.33,Male,0,40,...
...
|
A dataset is firstly described, beginning with the name of the dataset (or the relation in ARFF terminology). Each of the variables (or attribute in ARFF terminology) used to describe the observations is then identified, together with their data type, each definition on a single line (we have truncated the lines in the above example). Numeric variables are identified as numeric, real, or integer. For categoric variables we simply see a list the of possible values.
Two other data types recognised by ARFF are string and
date. A string data type simple indicates that the
variable can have any string as its value. A date data type
also optionally specifies the format in which the date is presented,
with the default being in ISO-8601 format which is equivalent to the
specification shown in Listing ![[*]](crossref.png) .
.
[float,caption={ARFF ISO-8601 date
specification},label={lst:arff.data.specification}]
|
The actual observations are then listed, each on a single line, with fields separated by commas, much like a CSV file.
Comments can be included in the file, introduced at the beginning of a
line with a %, whereby the remainder of the line is ignored.
A significant advantage of the ARFF data file over the CSV data file is the meta data information. This is particularly useful in Rattle where for categoric data the possible values are determined from the data (which may not included every possible value) rather than from a full list of possible values.
Also, the ability to include comments ensure we can record extra information about the data set, including how it was derived, where it came from, and how it might be cited.
Missing values in an ARFF dataset are identified using the question
mark ?. These are identified by read.arff
underneath and we see them as the usual NA in Rattle.