Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
|





|
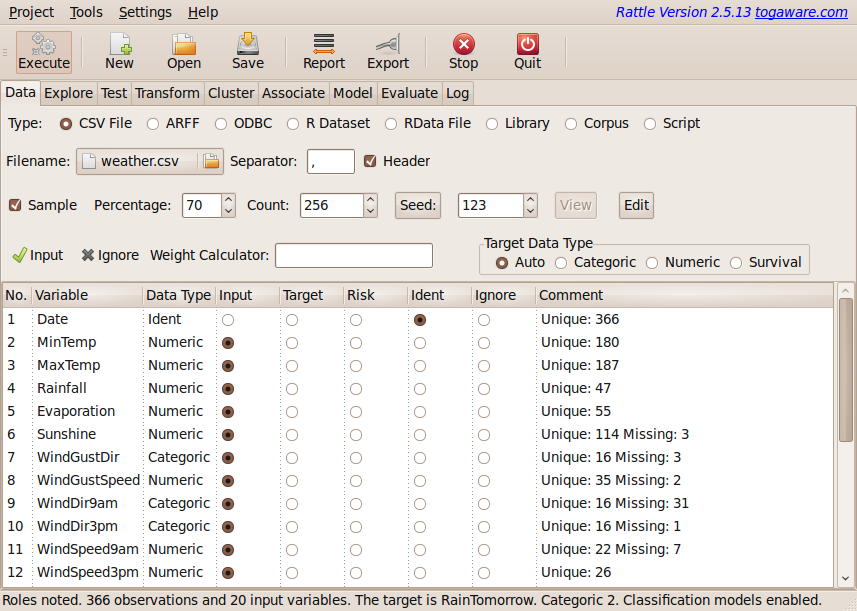
The Data tab is the starting point for Rattle and where we load our dataset. Rattle is able to load data from various sources. Support is directly included for comma separated data files (.csv files as might be exported by a spreadsheet which use commas to separate variable values in a record--see Section 4.3), tab separated files (.txt, which are also commonly exported from spreadsheets and use the tab character to separate columns, rather than commas), a common data mining dataset format used by Weka (.arff files--see Section 4.5.1), and from an ODBC connection (thus allowing connection to an enormous collection of data sources including MS/Excel, MS/Access, SQL Server, Oracle, IBM DB2, Teradata, MySQL, Postgress, and SQLite--see Section 4.5.2).
When loading data into Rattle certain special strings are used to identify variable roles. For example, if the variable name starts with ID then the variable is marked as having a role as an identifier/ See Section 4.6.2 for details.
Of course, we don't need to use Rattle to load a dataset. We could simply use the underlying R commands to do the same. In fact, it is instructive to review the underlying R commands that Rattle is relying upon:
> my.dataset <- read.csv(system.file("csv", "weather.csv",
package = "rattle"))
> head(my.dataset[,1:5])
|
Date Location MinTemp MaxTemp Rainfall
1 2007-11-01 Canberra 8.0 24.3 0.0
2 2007-11-02 Canberra 14.0 26.9 3.6
3 2007-11-03 Canberra 13.7 23.4 3.6
4 2007-11-04 Canberra 13.3 15.5 39.8
5 2007-11-05 Canberra 7.6 16.1 2.8
6 2007-11-06 Canberra 6.2 16.9 0.0
|
Notice that to the head function we supply only the first 5 columns of the dataset (otherwise we will have all columns listed, filling up the page).
The details of reading data into R are covered in Chapter 4 but as an exercise we can use the help function to get an idea of what is happening here:
> help(system.file) > help(read.csv) |
Do take a moment to read this documentation and dissect the above example of reading the weather dataset.
Underneath Rattle, R is very flexible in where it obtains its data from, and data from almost any source can be loaded. Consequently, Rattle is able to access this same variety of sources. It does, however, require the loading of the data into the R console and then within Rattle loading it as an R Dataset. All kinds of additional data sources can be loaded directly into R--including loading data directly from SAS, SPSS, Minitab, Oracle, MySQL, and SQLite, as well as data formats including NCSA's HDF5 (Hierarchical Data Format) and UCAR's NETCDF (Network Common Data Form) formats.
Once a dataset has been identified and the tab executed the data will be displayed in the textview. Figure 4.1 displays the Rattle window after loading the weather.csv which is supplied as a sample dataset with the Rattle package.