
Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
The Evaluate Tab |





|
The Evaluate tab displays all the options available for evaluating the performance of our models, and for deploying the model over new datasets.
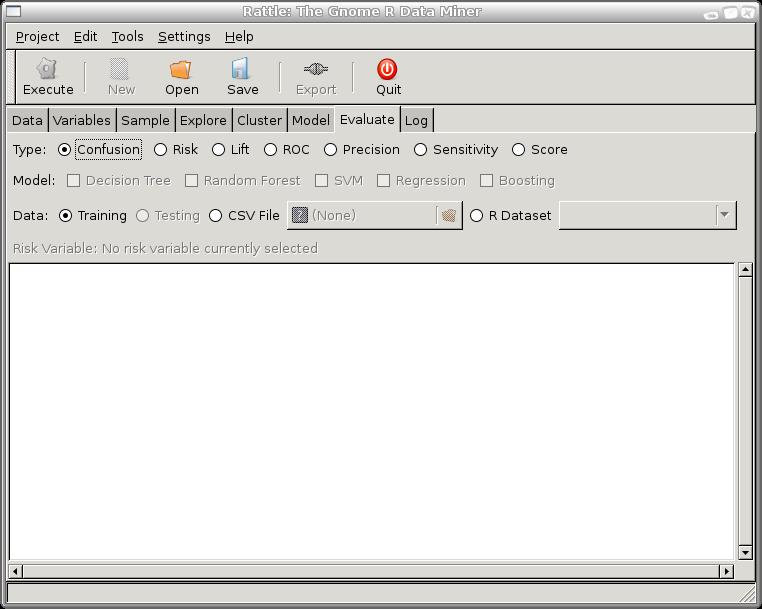
The range of different types of evaluations is presented as a series of radio buttons, allowing just a single evaluation type to be chosen at any time. Each type of evaluation is presented in the following sections of this chapter.
Below the row of evaluation types is a row of check boxes to choose the model types we wish to evaluate. The check boxes are only sensitive once a model has been built, and so on a fresh start of Rattle no model check box can be checked. As models are built, they will become sensitive, and as we move from the Model tab to this Evaluate tab the most recently built model will be automatically checked (and any previously checked Model choices will be unselected). This corresponds to a common pattern of behaviour, in that often we will build and tune a model, then want to explore its performance by moving to this Evaluate tab. If the All option has been chosen of the Model tab then all models that were successfully built will automatically be checked on the Evaluate tab.
To evaluate a model we need to identify a dataset on which to perform the evaluation.
The first option (but not the best option) is to evaluate our model on the training dataset. This is generally not a good idea, and the information dialogue shown here will be displayed each time we perform an evaluation on a training dataset. The output of any evaluation on the training dataset will also highlight this fact. The problem is that we have built our model on this training dataset, and it is often the case that the model will perform very well on that dataset! It should, because we've tried hard to make sure it does. But this does not give us a very good idea of how well the model will perform in general, on previously unseen data.
For a better guide to how well the model will perform in general, that is, on new and previously unseen data, we need to apply the model to such data and obtain an error rate. This error rate, and not the error rate from the training dataset, will then be a better estimate of how well the model will perform.
We discussed the concept of a training set in Section 5.7.1, presenting the Sample option of the Data tab which provides a simple but effective mechanism for identifying a part of the dataset to be held separately from the training dataset, and to be used explicitly as the testing dataset. As indicated there, the default in Rattle is to use 70% of the dataset for training, and 30% for testing.
Todo: Dataset from CSV file
Todo: Dataset from R
The final piece of information displayed in the common area of the
Evaluate tab is the Risk Variable. The concept of the Risk
Variable has been discussed in Section ![[*]](crossref.png) . It is
used as a measure of how significant each case is, with a typical
example recording the dollar value of the fraud related to the
case. The Risk Chart makes use of this variable if there is one, and
it is included in the common area of the Evaluate tab for
information purposes only.
. It is
used as a measure of how significant each case is, with a typical
example recording the dollar value of the fraud related to the
case. The Risk Chart makes use of this variable if there is one, and
it is included in the common area of the Evaluate tab for
information purposes only.
